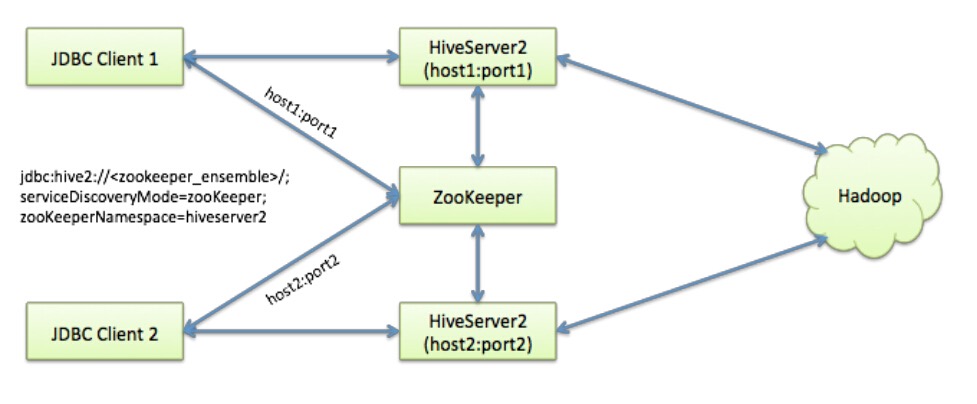
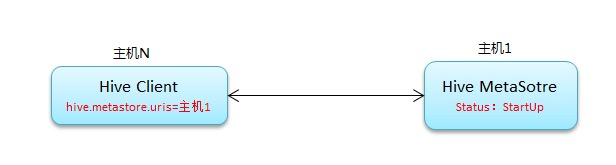
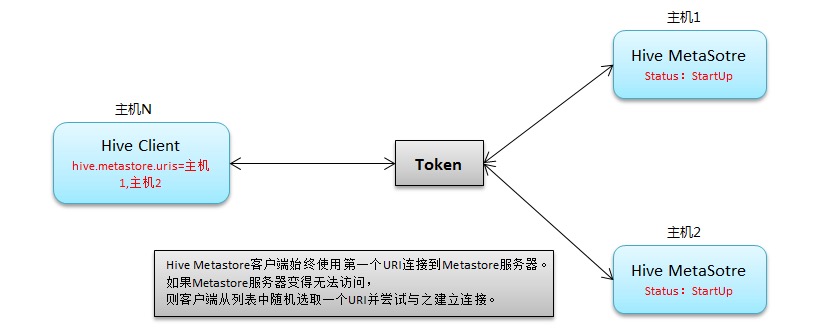
Hive从0.14开始,使用Zookeeper实现了HiveServer2的HA功能(ZooKeeper Service Discovery),Client端可以通过指定一个nameSpace来连接HiveServer2,而不是指定某一个host和port,本文学习和研究HiveServer2的高可用配置。
[root@node01 ~]# beeline WARNING: Use "yarn jar" to launch YARN applications. SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Beeline version 2.1.1-cdh6.3.2 by Apache Hive beeline> beeline> !connect jdbc:hive2://node01:2181,node02:2181,node03:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk Connecting to jdbc:hive2://node01:2181,node02:2181,node03:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk Enter username for jdbc:hive2://node01:2181,node02:2181,node03:2181/: hive Enter password for jdbc:hive2://node01:2181,node02:2181,node03:2181/: 21/07/01 09:31:18 [main]: INFO jdbc.HiveConnection: Connected to 0.0.0.0:10001 Connected to: Apache Hive (version 2.1.1-cdh6.3.2) Driver: Hive JDBC (version 2.1.1-cdh6.3.2) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://node01:2181,node02:2181,node0> show tables; INFO : Compiling command(queryId=hive_20210701093131_c1958b66-3e2a-443d-8562-22f00f4bb463): show tables INFO : Semantic Analysis Completed INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null) INFO : Completed compiling command(queryId=hive_20210701093131_c1958b66-3e2a-443d-8562-22f00f4bb463); Time taken: 1.164 seconds INFO : Executing command(queryId=hive_20210701093131_c1958b66-3e2a-443d-8562-22f00f4bb463): show tables INFO : Starting task [Stage-0:DDL] in serial mode INFO : Completed executing command(queryId=hive_20210701093131_c1958b66-3e2a-443d-8562-22f00f4bb463); Time taken: 0.046 seconds INFO : OK +-----------+ | tab_name | +-----------+ | score4 | | stu | +-----------+ 2 rows selected (1.728 seconds)