

最全面的数仓分层剖析,一文搞定企业数仓分层
数仓在建设过程中,对数据的组织管理上,不仅要根据业务进行纵向的主题域划分,还需要横向的数仓分层规范 。
前言
从事数仓相关工作的人员都知道数仓模型设计的首要工作之一就是进行模型分层,可见模型分层在模型设计过程中的重要性,确实优秀的分层设计是一个数仓项目能否建设成功的核心要素,让数据易理解和高复用是分层的核心目标。
早期作者在考虑对公司数仓指定分层规范时,也是查了很多资料,网上资料也是较为全面,有使用阿里大数据分层方案,也有分三层、或者四五层的都有,这么多分层思路,让作者一阵脑瓜疼。所以作者希望整理一篇文章,对数仓分层进行一个较为全面的剖析,讲下自己对分层的见解和想法,和大家交流。
本文将对数据仓库分层方法进行全方位的阐述和整理,具体包含如下内容:
1、介绍为什么分层,分层的作用,核心思想
2、提出一种通用的数据分层设计,以及分层设计的原则
3、一些不同的分层思路,各个大厂分层及思路讲述
4、讲述可落地的实践意见
数仓分层意义,也可以说数仓为什么分层?
通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,每一层的处理逻辑都相对简单和容易理解,从而达到解耦的目的,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,方便问题排查和追溯定位。
数仓分层的核心思想?
分层的核心思想就是解耦,再解耦,把复杂的问题简单化,这直接影响了数据架构到底分几层。

数仓分层的好处
数据分层将可以给我们带来如下的好处:
1、清晰数据结构:每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解
2、减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算
3、统一数据口径:通过数据分层,提供统一的数据出口,统一对外输出的数据口径
4、复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题
一种通用的分层架构
这里介绍一种较为常见,也是适用性较广的四层分层架构,至于出处的话,我感觉应该是阿里吧,感兴趣的同学可以看下《大数据之路:阿里巴巴大数据实践》这本书中有介绍。
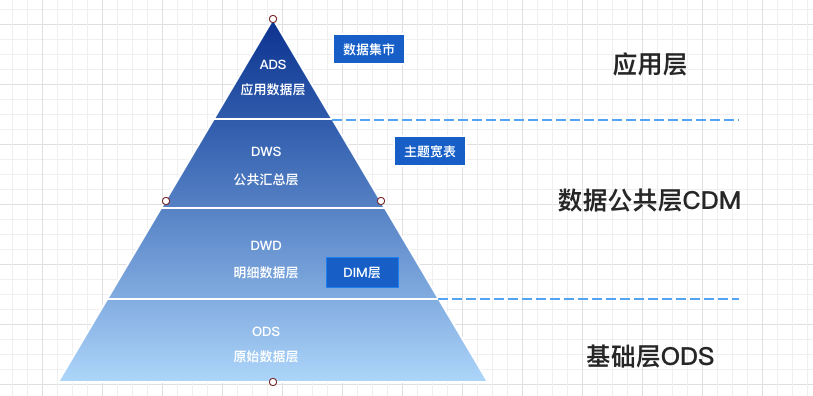
| 层级 | 说明 | 描述 | 备注 |
|---|---|---|---|
| ODS (Operation Data Store) | 原始数据层 | 存放未经过处理的原始数据至数据仓库系统,结构上与源系统保持一致,是数据仓库的数据准备区,数据原则上全量保留 | |
| DWD(Data Warehouse Detail) | 明细数据层 | 以业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细层事实表。数据粒度一般保持和ODS层一样的,并且提供一定的数据质量保证。同时为了提高数据明细层的易用性,该层会采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联。同时在此层会采用明细宽表,复用关联计算,减少数据扫描。 | 数据公共层CDM |
| (Data WareHouse Summary) | 公共汇总层 | 以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段物理化模型。构建命名规范、口径一致的统计指标,为上层提供公共指标,建立汇总宽表、明细事实表。 | 数据公共层CDM |
| DIM(Dimension) | 公共维度层 | 基于维度建模理念思想,建立整个企业的一致性维度。降低数据计算口径和算法不统一风险 | 数据公共层CDM |
| ADS(Application Data Service) | 数据应用层 | 数据应用层,也叫DM(数据集市)或APP层等,面向实际的数据需求,可以直接给业务人员使用,以DWD或者DWS层的数据为基础,组成各种统计报表。除此之外还有一些直接的表现形式,例如主题大宽度表集市,以及横表转纵表等。 |
数据公共层CDM(Common Data Model)或者 企业级数据仓库EDW (Enterprise Data Warehouse)主要用于存放明细事实数据、维表数据及公共指标汇总数据,其中明细事实数据、维表数据一般根据ODS层数据加工生成;公共指标汇总数据一般根据维表数据和明细事实数据加工生成。本层采用维度模型作为建模方法的理论基础,更多的是通过采用一些维度退化手段,将维度退化至事实表中,减少维表和事实表的关联,提高数据易用性。
一些不同的分层思路(大厂数仓分层案例)
爱奇艺数仓分层架构
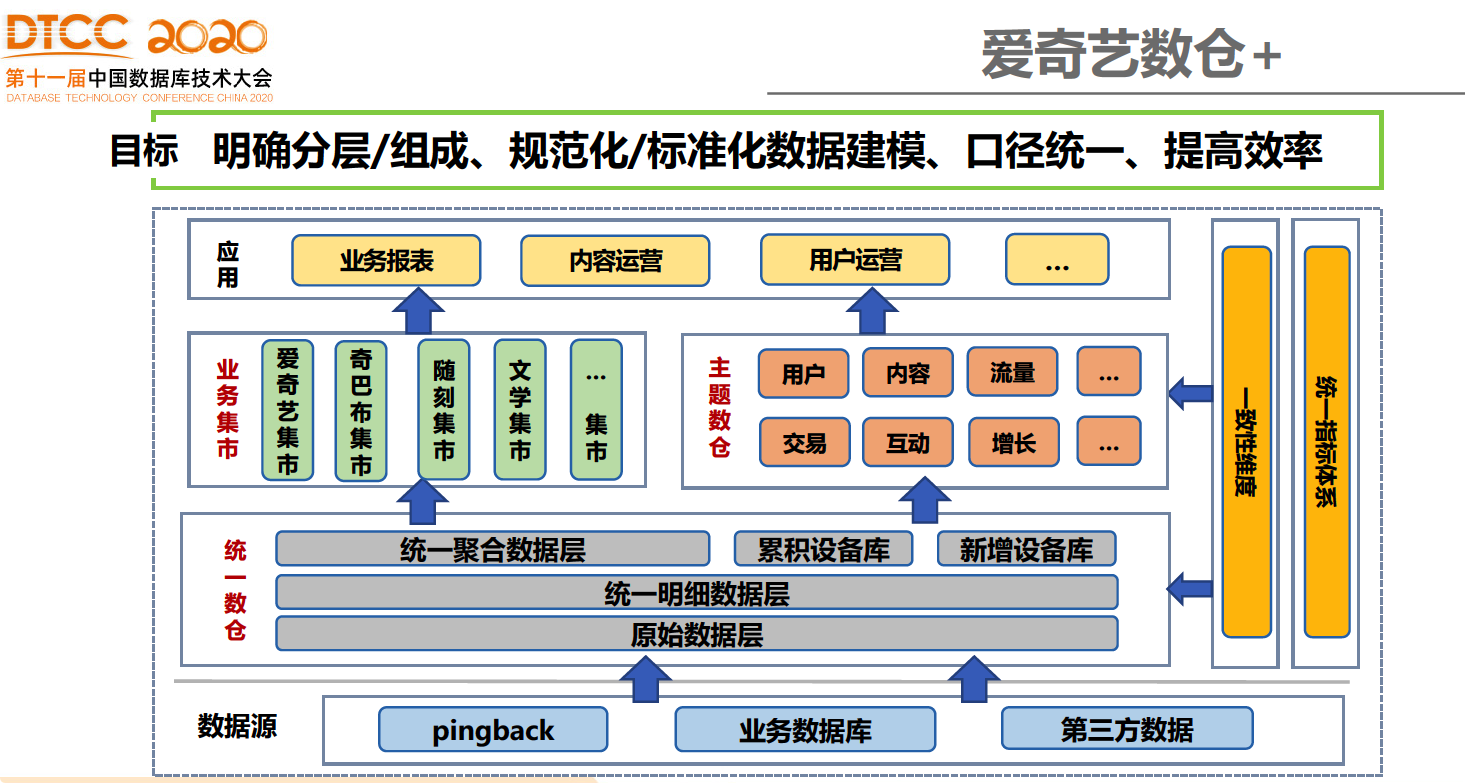
从上图可以看到,可以跟看到其实分层和通用的分层架构其实差别不太大,也是包含原始数据层、明细层,汇总层、应用层以及统一的维度层,下面主要介绍一些不同的地方。
爱奇艺的架构中,最底层是统一数仓,其实是将原始数据层、统一明细数据层和统一聚合数据层进行了整合。明细层负责对接下层所有的原始数据,百分之百还原所有业务域和业务过程的数据,同时屏蔽底层原始数据变动对上层造成的影响,是整个爱奇艺数仓的底层基础。
最底层是统一数仓,主要分为统一明细数据层和统一聚合数据层。明细层负责对接下层所有的原始数据,百分之百还原所有业务域和业务过程的数据,同时屏蔽底层原始数据变动对上层造成的影响,是整个数仓 2.0 的底层基础。
通过明细层完成业务关系到数据关系逻辑转换,并补充相关的维度,保存最细粒度数据,进行复杂业务逻辑分离、数据清洗、统一规范化数据格式等 ETL 过程。
聚合层负责对通用的指标进行沉淀,向上提供统一口径的计算指标,同时避免重复计算。除此之外,还会提供基于 OneID 体系的统一累计设备库和新增设备库供上层使用。
业务集市主要以业务诉求为主,建设满足业务分析的各种数据集合。在业务集市建设过程中,按照尽可能细的粒度去划分业务集市,且每个业务集市之间不会出现数据依赖和横向引用,在应用层可以跨集市进行汇总计算对外提供数据服务。这样做的好处是,如果出现一些组织架构调整或者工作职责的变更等情况,每个业务集市无需调整,只需在应用层做相应的修改即可,同时也避免因为计算任务代码混在一起、数据权限拆分等问题带来的数据变更成本。
主题数仓以公司范围内公共的主题域/主题角度,以一致性维度为基础,跨各业务做数据的整合分析和相关建设,包括流量数仓、内容数仓、用户数仓等。
应用层包括业务报表、内容分析、用户运营等数据应用产品,按照具体的场景和需求,从业务集市和主题数仓获取数据。
SaaS收银运营数仓分层架构

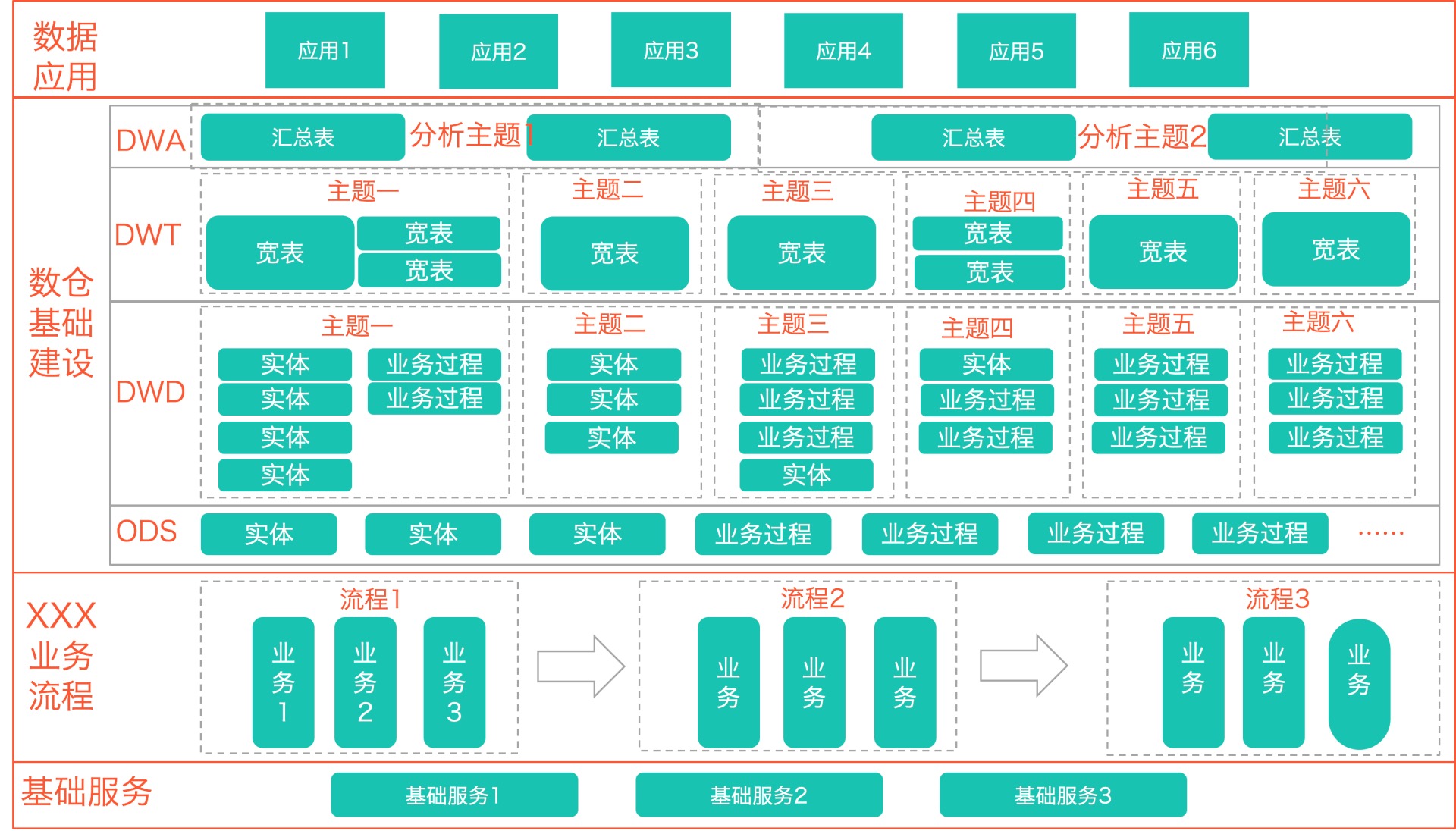
这里作者的案例是美团站点分享的SaaS收银运营数仓建设一文中的架构,这个分层架构大概是五层,虽然从名称上看着和通用分层架构差异比较大,实际具体功能上,只是增加了一个DWT主题宽表层,APP层和通用的ADS层作用基本一致,DWA汇总层其实和通用的DWS层是类似的。
DWT层主题宽表层,其实是对DWD各层的信息进行join整合,基于主题,将业务过程相关的数据冗余处理,从而方便上层DWS汇总数据使用。
美团数仓分层架构
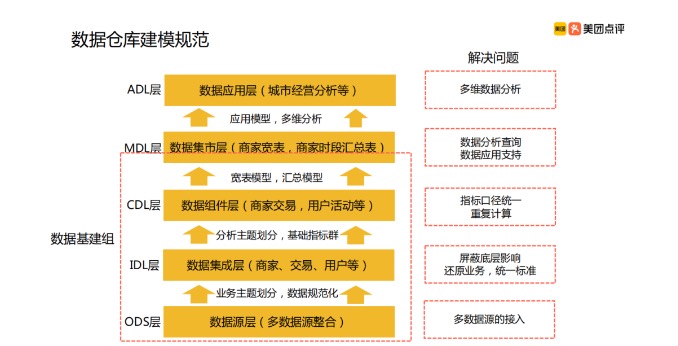
从上图中,看起来美团数仓分层架构和通用分层架构也是差异较大,但是其实和通用的分层架构也是异曲同工,只不过是将数据分的更新,做更多的解耦。
ODS数据源层不用多说,名字都和通用的原始数据层一致,下面主要说下上面四层:
IDL数据集成层,整合多数据源的一致性建模,完成数据维度,事实组合。这一层要注重特殊的两个概念,一是宽表,二是聚合表。宽表与 kimball 的 fact table 不一样,我们通常所说的fact table,实际上仅仅是明细表的统称,而宽表,则是把相关的事实表,都整合到一起,这样的好处,一是加快速度,二是一次查询更加全面。这快你看和《SaaS收银运营数仓建设》案例中的DWT又是何其相识。
CDL数据组件层,用来完成聚合汇总,进一步按照粒度划分,完成年月日级的聚合。至此,一个中央数据仓库就完成了。
MDL数据及时层,按照业务单元,做数据集市。比如营运,销售。这样提供给数据应用层,就有了完整的、可复用的数据源。
1M0t81
最终的ADL应用层,会简单很多,主要是选型,也就是针对业务数据应用,会选择哪些数据库技术,分析引擎技术,还有报表计算,归纳起来,离不开存储,计算,可视化。
网易严选数仓分层架构
这里稍微简单说下吧,其实网易严选数仓分层架构和通用数仓分层架构差别不大,也算是直观的使用体现吧。
严选数仓分层模型将数据分为三层,ods,dw和dm层。其中ods是操作数据层,保留最原始的数据;dw包含dwd和dws层,这两层共同组成中间层;dm是应用层,基于dw层做汇总加工,满足各产品、分析师和业务方的需求。
| 层级 | 说明 | 描述 | 备注 |
|---|---|---|---|
| ODS (Operation Data Store) | 操作数据层 | 不对外开放,把业务系统数据同步到数仓。数据格式保留业务系统的数据格式;目前主要通过datahub解析binlog来实现的,目前严选的ods层数据同步主要以全量数据为主。 | |
| DWD(Data Warehouse Detail) | 明细数据层 | 对外开放,主要作用是沉淀一些公共的逻辑,常用维度属性的关联等,下游经常在一起使用的模型会在这一层做宽表处理,减少事实表和维表的关联,减少重复的关联加工。 | dw层 |
| (Data WareHouse Summary) | 公共汇总层 | 对外开放,主要沉淀严选数据的公共指标,dws层是整个严选数据对外开放和使用的核心,是严选最核心的数据资产。 | dw层 |
| DIM(Dimension) | 公共维度层 | 对外开放,主要是一些常用维表,比如商品维表、sku维表、渠道维表。 | dw层 |
| DM | 应用层 | 对产品开放使用,支持数据产品、报表的使用,主要是不公用复杂指标的汇总和计算。 |
网易云音乐数仓分层架构
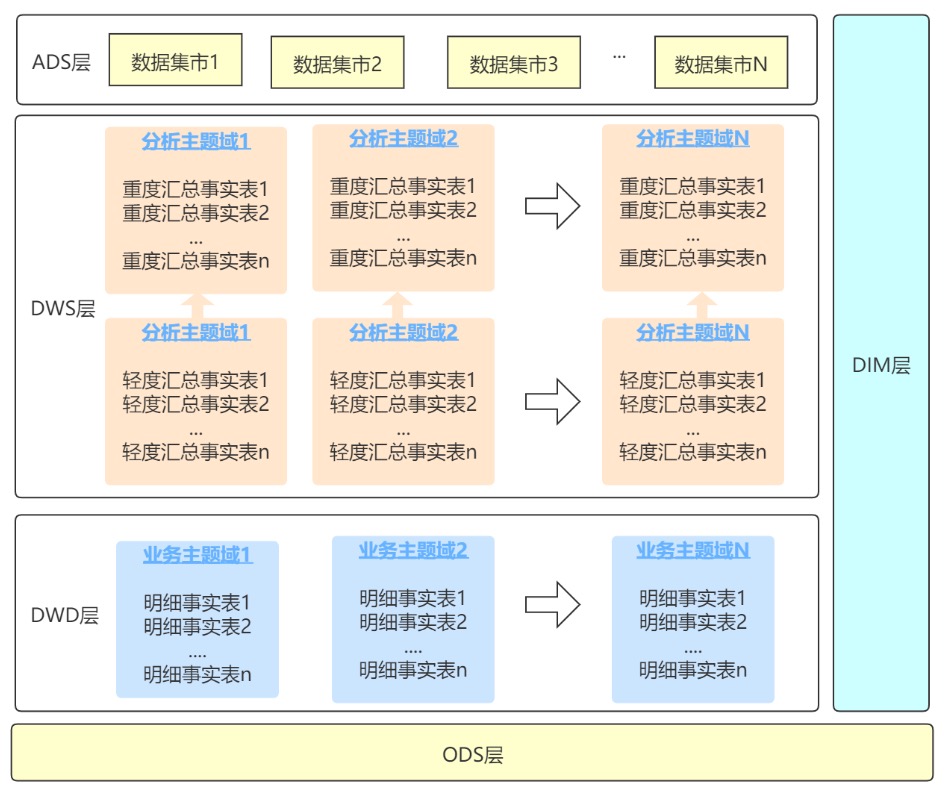
分享作者数仓分层架构
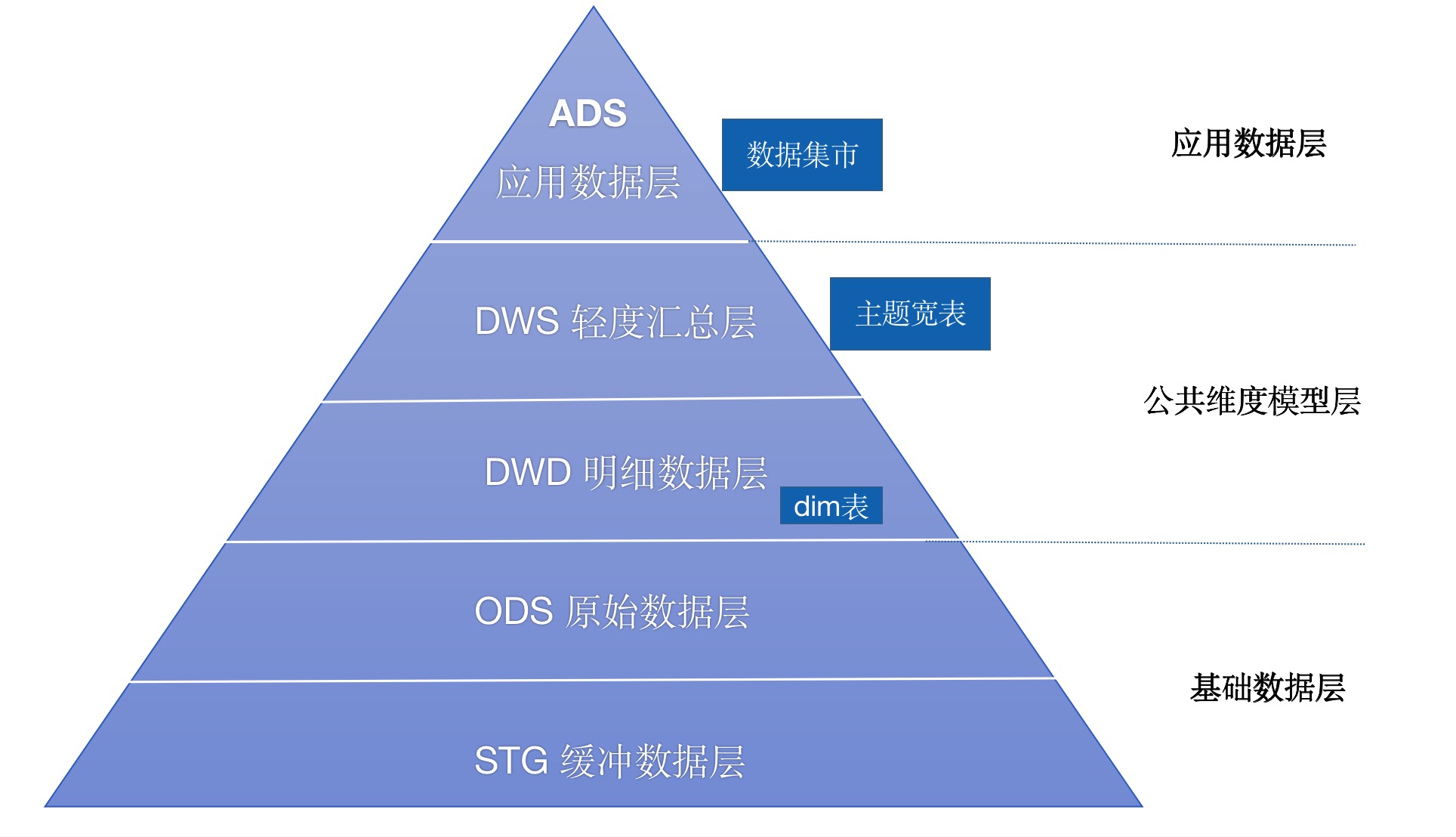
不多说,这里不同之处在与增加了stg缓冲层,用于存储每天的增量数据和变更数据,配合ODS对数据进行沉淀,减少了抽取的复杂性,比如进行增量数据的合并操作等。
讲一下个人对如何设计数仓分层架构的想法(数仓到底分几层)
数据仓库分层没有绝对的规范,适合的就是最好的,至于分几层,建议按照目前的业务和建设现状,进行合理解构和分层设计,一般刚开始做,建议3、4层。规划1-1.5年的架构,然后不断的建设、优化、再优化。不断逼近满足所有需求。
下面针对一些场景说下分层的想法:
场景一:时间紧任务重,急于看结果
这种场景,直接连各个业务数据库,抽取数据到大数据平台,根据需求组合join或者汇总count、sum就行,就不要不分层了,作者现在公司服务的数仓项目前身就是这样,将各个业务系统数据抽取到oracle,你看都没有大数据平台就做了。
场景二:公司业务简单,且相对比较固定,数据来源不多,结构也很清晰,需求也不多
那么还弄啥来,直接使用通用的数仓架构就行,ODS起到解耦业务数据库+异构数据源的问题,DWD解决数据脏乱差的问题,DWS服用的指标计算,ADS直接面向前台业务需求。
场景三:公司业务复杂,业务变化较快
那就多一层DWT层做汇总,多一层解耦,业务变化的时候,我们只改DWS层就好了,最多穿透到DWT层。业务变化的时候调整一下,工作量也不会太大,最重要的是能保证底层结构的稳定和数据分析的可持续性。
场景四:公司业务较为复杂,集团性公司,下辖多个bu,bu间业务内容交叉不大
可以在数仓通用分层架构上,增加一层DM层,也就是数据集市层,各个数据集市层,单独供数,甚至有单独的计算资源,这样可以避免因为计算任务代码混在一起、数据权限拆分等问题带来的数据变更成本。
一个好的数仓模型分层,应该具备的要素
一个好的数仓模型分层,应该具备的要素是数据模型可复用,完善且规范的。
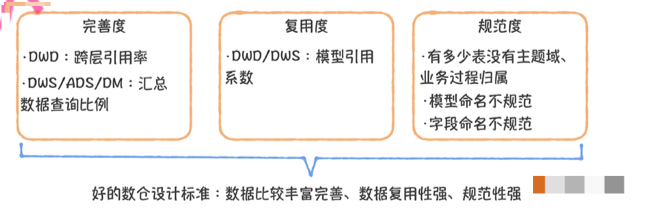
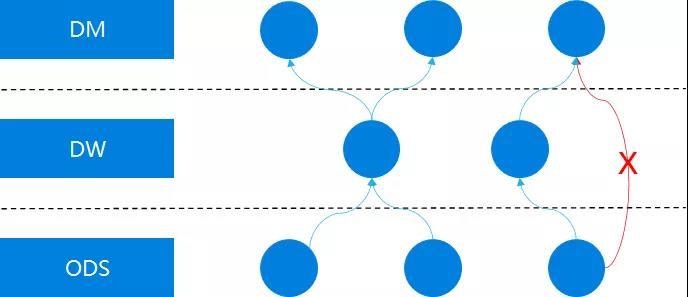
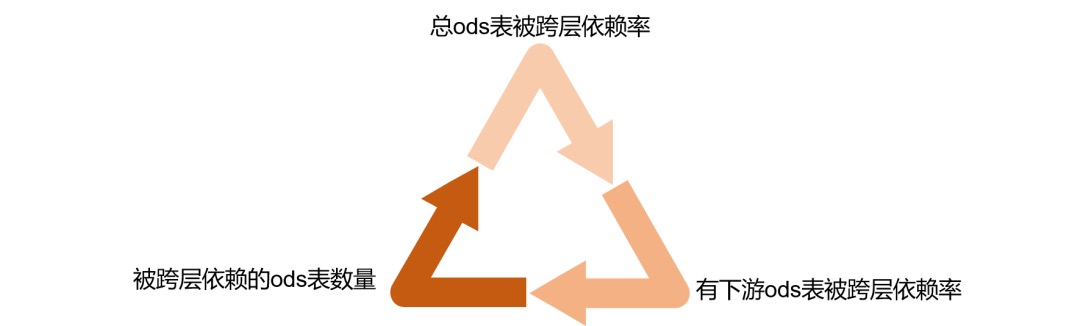
从完善度上来讲,主要衡量DWD层和汇总层两块的完善度,DWD层完善度,主要是希望DWD等尽可能被汇总层引用,ODS层被除了DWD层外的尽可能少的引用,最好是没有。
从复用度上来讲,我们希望80%需求由20%的表来支持。直接点讲,就是大部分(80%以上)的需求,都用DWS的表来支持。
从规范度上来讲,主要从表名、字段名来看,一个规范的表名应该包括层级、主题域、分区规则,抽取类型等信息。
字段规范应该是和词根一直,同字段同名等,具体这块可以看作者写得《数仓命名规范篇》
总结
数据仓库分层没有绝对的规范,适合的就是最好的,数据仓库分层的核心逻辑是解耦,在有限时间、资源等条件下满足业务需求,同时又要兼顾业务的快速变化。所以我们作为数据架构师,需要兼顾业务的复杂变化,以及开发的复杂度和可维护性,在两者之间做一个平衡和取舍,选择合适的分层架构。
另外分层架构是需要不断的优化调整的,不能超前太多,也不能脱离业务。按照Inmon和Kimball吵了十几年的经验上看,建议架构设计时,按超越当前实际情况1~1.5年的设计是比较合适的。






